
Splunk!
Recently I participated in the Splunk Workshop at SMTware. You might recall these names as SMTware gave us a peek into Splunk during a Login Lite session. Being intrigued by this session so I instantly signed up for the workshop. So I attended this session and I would like to share my experience.
Just to give an example of the versatility of Splunk ; Prior to the workshop I needed to gather some information from a RES Powerfuse to determine which application created a certain UPF file. So I created a building block of a massive 230 mebibytes which I opened in my favourite text editor (Crimson Editor). After mocking around with macro’s I decided this wasn’t the way to go.
So next step; I got my way into SED, GAWK, GREP and other Linux based tools which usually wil do the trick for me. Well the big chunk of data wasn’t really helping out and this also led into a mystified cloud of information. Untill I gave Splunk a try, installing is easy as 1-2-3 and done in a jiffy. Imported the XML file and run a fairly simple search query and Bob was my uncle again.
I got the results within a split second. Simply amazing! For the workshop we went throught the undermentioned topics, which I will briefly summarize.
What is Splunk exactly?
-
Splunk is a big-data-driven search engine for machine data. The software runs on Windows, OSX and various Linux flavours and is able to gather information from numerous devices and operating systems. Looking at the program structure you will notice that the system is developed on a Linux platform and ported to others.
-
Splunk is able to provide visibility, reporting and searched across the (real time) indexed information from a intuitive web interface.
-
The system is very easy to install and use, depending on the use case. The flexibility of the software allows you to create various levels of reporting from fairly easy to extranormous complicated queries/data models.
-
You can either install this software on premises or use the SAAS – Splunk Storm environment.
How does it work? Splunk is able to work in two different ways;
-
Agentless; meaning that the Splunk system needs to be up to perform data harvesting. The down-side is that when the splunk environment is not available it is possible that, i.e. syslog information gets lost in time.
-
Splunk Forwarder; meaning a small service/daemon needs to be installed locally on the source-machine. This, small foot-printed/light-weighted, software takes care of the secure and validated processing of the machine data.
Splunk gathers ALL information from the distributed nodes and gathers the information as a unstructured data blob, based on a flat file system. This enables to have all information available at all times, unlike the traditional monitoring systems, which usually narrow downs information of interest, leaving out the possibility of deep dive in to the complete chain of all the data, see below:
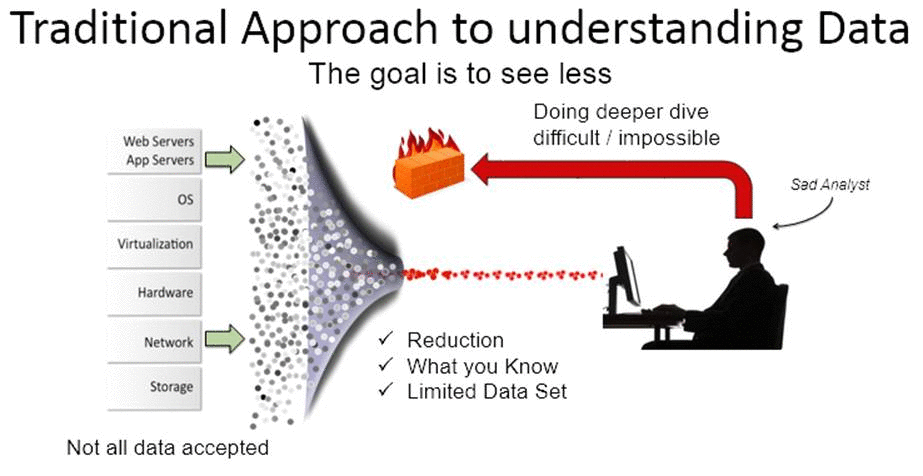 versus
versus
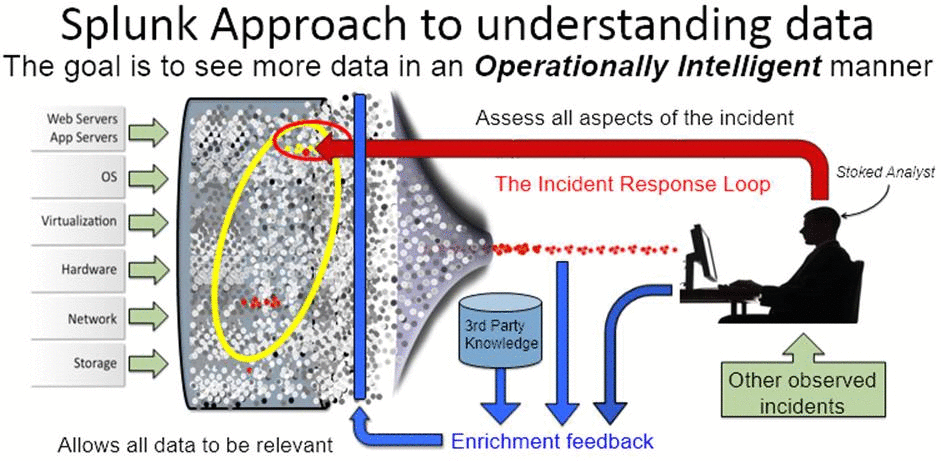
What can Splunk do for you?
The following functions are scalable and can be divided or combined on one or multiple nodes.
-
Search Head -> Searching and Reporting
-
Indexer -> Index and Search Services, using MapReduce methodology, like Google does.
-
Deployment server -> Local and Distributed config management
- Forwarder -> Data Collection and Forwarding, parallel processing to reduce load
How does Splunk handle privacy, security and regulated control?
-
Splunk is able to anonymise/mash-up data to conceil unwanted data.
- Role-based viewing of the indexes to provide comprehensive control for data security, retention times and data integrity.
### How does the so-called “universal indexing”work?
- Breaking the indexable data in to fine-grained segments Splunk is able to determine/discover a structure in the data itself. This is highly configurable but works out-of-the-box really well.
- Splunk’s ability to marry the flexibility of unstructured search with the power of working with structured data.
- Use event types and transactions to group together interesting sets of similar events, this creating more insight on the chain.
- Tags and aliases are used to manage and normalize sets of field information.
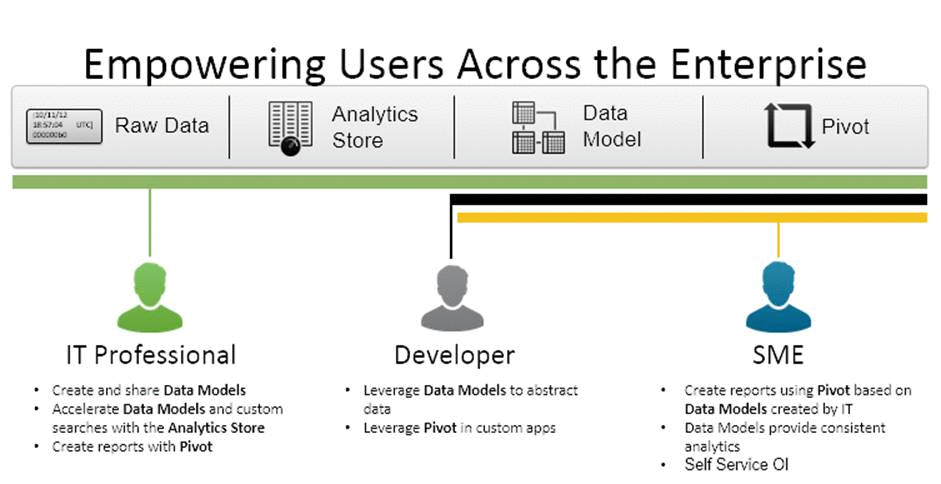
### Who can benefit from Splunk?
The complete chain of users can benefit from the results in the different roles, i.e.;
- IT Professional, from creating data model to creating reports.
- Developer, leveraging the data models and creating custom apps.
- Subject Matter Experts, modelling report for the specific business needs.
- In the end the complete business can benefit based on the analytics given.
Conclusion
I think that in this world of analytics and continuous strive for performance enhancement this is a very good tool to use. However it comes with a price-tag, unless you keep the ‘indexed data’-per-day as low as 500mebibytes you are free rider. See you at the ‘Splunk Live!’ event , I got my ticket already in the pocket!
For some plugins/apps look here